



Want to know how much website downtime costs, and the impact it can have on your business?
Find out everything you need to know in our new uptime monitoring whitepaper 2021
In this post, we’ll take you through the available options for managing sub-accounts, from managing permissions in app, to our new functionality which allows you to assign individual API keys to your users. First let’s take a look at our new API Key Management feature with support for multiple API Keys.
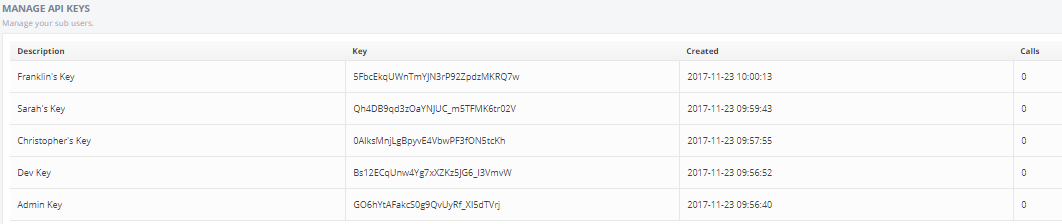
It’s now possible to add multiple API keys to an account, this means that for teams the same key will no longer need to be shared, and each member of staff/department can be assigned their own access token.
As well as being an improvement security wise, you can monitor the usage for each key in the API Key’s section of the user menu, to do this – and to add new keys for your team simply click here.
On our Business level plan it’s possible to add Sub-Users who have access to the in-app data, this allows them to view the information in a much more visual fashion when compared to the API. Sub-Users will be able to view the full settings and details of the tests on the “Main Account” depending on the permissions that they are assigned.
You can assign a few different parameters to your Sub-Users, first off you should decide whether they will have “view-only” or “full-edit” rights which will affect how they can interact with the test data from the main account.
Another handy option that can be set is tag based access, this means that you can assign a Sub-User to one or more test tags, and when they log in it’s only the tests under these tags that they will be able to see and interact with.
